


One Source of Truth
Marquez enables consuming, storing, and visualizing OpenLineage metadata from across an organization, serving use cases including data governance, data quality monitoring, and performance analytics.
Marquez was released and open sourced by WeWork.
One Service for Lineage

Real-time metadata server
Marquez includes a metadata server offering an OpenLineage-compatible endpoint for real-time collection of information from running jobs and applications.
As the reference implementation of OpenLineage, the Marquez API server already works with all the integrations developed by the OpenLineage community. This includes Apache Airflow, Apache Spark, Apache Flink, dbt, and Dagster.
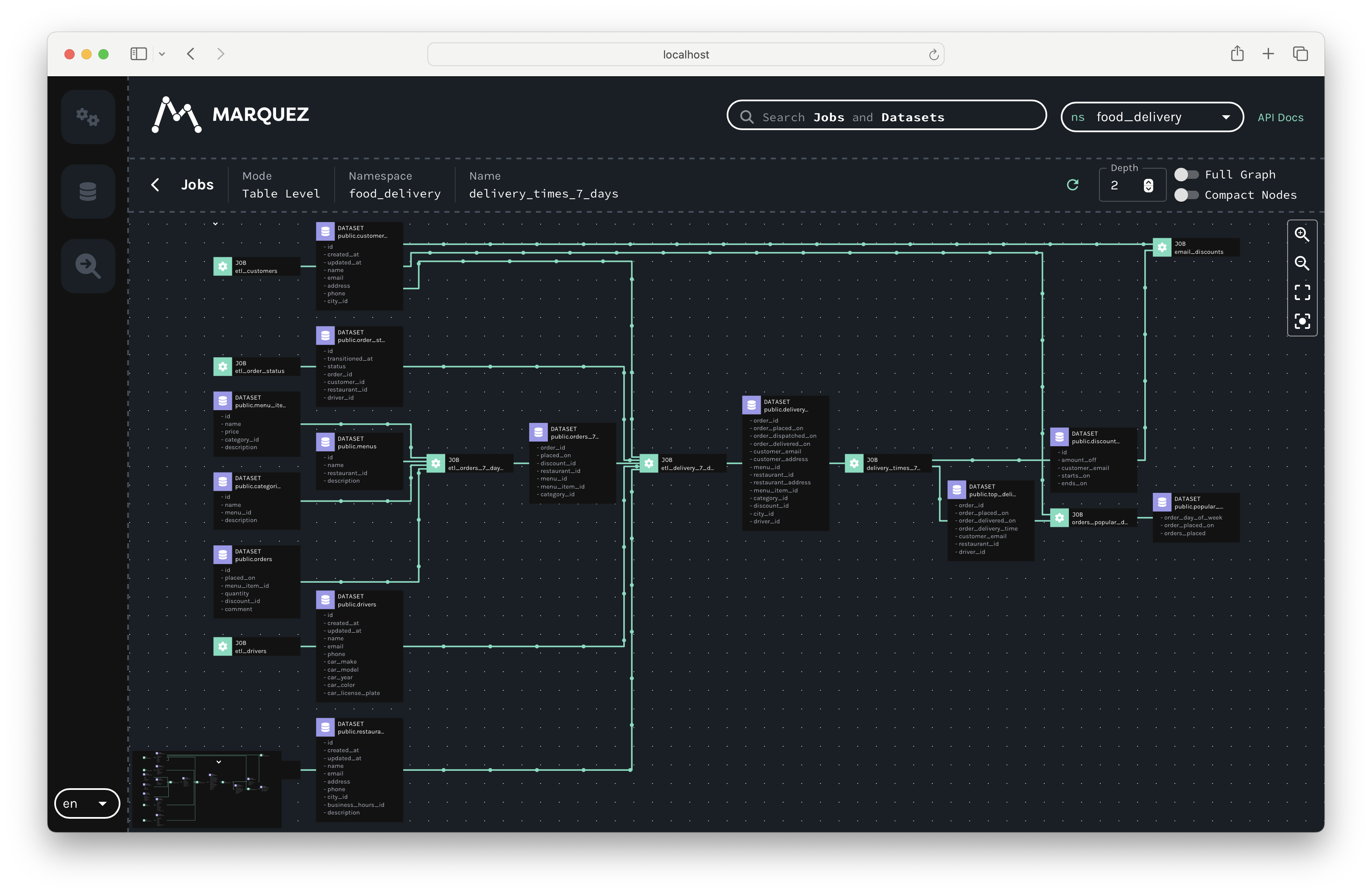
Unified visual graph
Through a web user interface, Marquez provides a visual map that shows complex interdependencies within your data ecosystem.
The user interface allows you to browse the metadata within Marquez, making it easy to see the inputs and outputs of each job, trace the lineage of individual datasets, and study performance metrics and execution details.
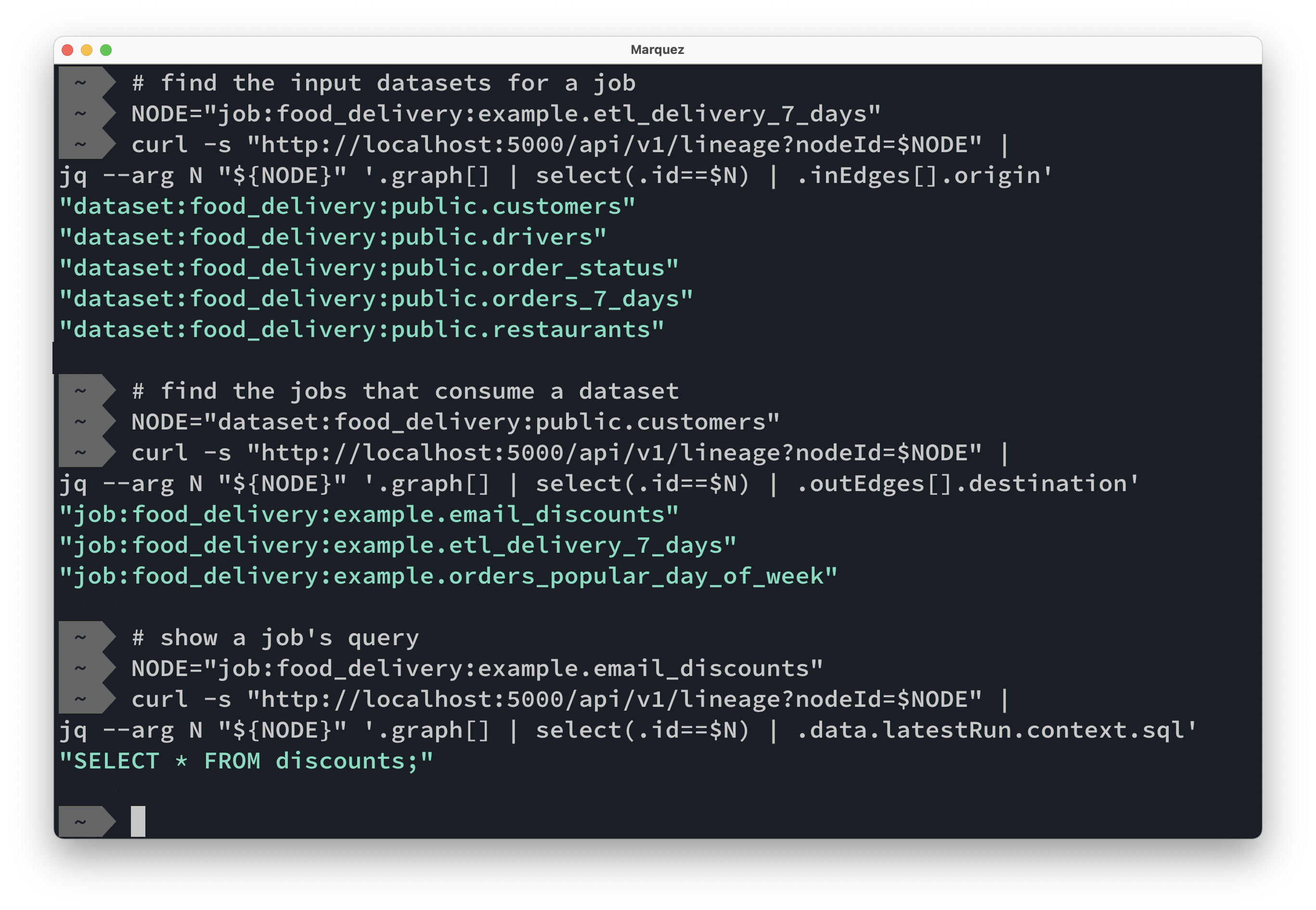
Flexible Lineage API
Through a lineage API, metadata can be queried for automation of key tasks like backfills and root cause analysis.
With the Lineage API, you can easily traverse the dependency tree and establish context for datasets across multiple pipelines and orchestration platforms. This can be used to enrich data catalogs and data quality systems.